.svg)
.svg)
How to manage the risk of AI agents

By Michael Domanic, Section Head of AI
Last week I ran an Agentic AI Office Hours for AI leaders, and my favorite question was one I get a lot: “We want to deploy agents, but how do we know what's safe to automate?”
The honest answer is that there’s no universal rule. It depends on your organization, your customers, and your appetite for things going wrong. But there is a framework I keep coming back to that helps make the decision concrete rather than abstract.
It comes down to two variables: blast radius and reversibility.
Blast radius is the level of damage something could potentially do if it goes wrong. An agent that drafts internal meeting summaries for your team has a small blast radius. If it gets something wrong, someone catches it and fixes it. An agent that sends client-facing deliverables has a larger one. If it communicates the wrong thing to a customer, your CSM probably has to get on the phone and eat crow. An agent that prescribes thousands of patient medications has a huge blast radius - people’s lives.
Reversibility is how easily you can undo or correct the outcome. An agent that generates a draft you can tweak before sending is highly reversible. An agent that pushes changes directly into your application layer, or sends information to external parties, much less so. Think about the Anthropic data leak - once information is out there, it's out there. That's not something you claw back.
These two variables give you a simple way to prioritize.
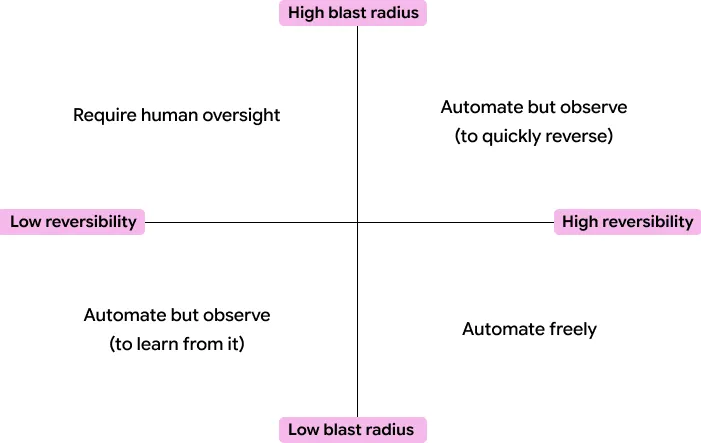
Low blast radius, high reversibility: Automate freely. This is where you want to start. Internal-facing agents, personal productivity tools, anything where the worst case is a few minutes of rework. There's very little risk in these, and they're where your team builds confidence and learns how agents actually behave.
Low blast radius, low reversibility: Automate but observe (to learn). The damage if something goes wrong is small, but you can’t easily undo it. Think of an agent that posts updates to an internal channel or logs data somewhere permanent. The stakes are low enough to let it run, but you want to be watching, to understand what the agent gets right and wrong so you can improve it before you point it at anything bigger.
High blast radius, high reversibility: Automate but observe to claw back. The potential damage is real, but you can catch and correct mistakes before they compound. An email draft that goes to a human for quick approval before it reaches a customer fits here. You're getting the speed benefit of automation while keeping the ability to intervene.
High blast radius, low reversibility: Require human oversight. This is where you don't take chances. Important client-facing deliverables, changes pushed into your application layer, anything where the wrong output can't be undone. Here’s an example: At Section, we send a client brief after every first call, to recap our conversation and give initial recommendations. We use AI in the process, but because the briefs go to executives, they require substantial human review - and often change significantly before sending.
Ultimately you want to build lots of low-blast radius, high-reversibility agents so that you learn what to avoid before you apply it to a higher-stakes situation. The goal isn't to avoid all mistakes. It's to make sure your early mistakes are cheap ones.
The broader point is this: if you're in the early stages of thinking about agents, start with low blast radius work and build from there. But don't stop at the easy stuff. You should also be thinking about the more complex, higher-stakes workflows where agents will eventually create the most value. The low-risk deployments are how you develop the organizational judgment to handle what’s next.

.png)
.svg)

.jpg)
.webp)